Daten mit curl herunterladen
 Das Kommando
Das Kommando curl ist eines der wenigen Kommandos – neben wget – für den Download von Daten über eine Shell Eingabeauffordung. Da es bei vielen Systemen bereits in der Minimalinstallation vorhanden ist lohnt es sich ein paar der Parameter und Vorgehensweisen bei der Arbeit mit curl kennenzulernen.
Herunterladen einer Datei
Für die Meisten ist bereits das Herunterladen einer Datei mit curl eine Herausforderung. Denn curl gibt die Datei direkt auf der Eingabeausfordung aus statt sie als Datei abzuspeichern.
Die Option -O vor der Download URL speichert die Datei unter dem gleichen Namen unter dem sie auf dem Server liegt. Falls der Server keinen Namen vorgibt, wird der letzte Anteil der URL als Name benutzt. Ein hinter -o (kleines o) angegebener Dateiname erzeugt stattdessen eine Datei mit dem Dateinamen.
Beispiele:
$ curl -O https://static.mylinuxtime.de/curl.txt
$ curl -o mein_curl.txt https://static.mylinuxtime.de/curl.txt
Die Option -O mehrfach mit einer folgenden URL angegeben lädt die Dateien der angegeben URLs herunter und speichert sie unter dem vom Server vorgegebenen Dateinamen.
Server mit selbstzertifiziertem Zertifikat
Obwohl es inzwischen die Möglichkeit gibt SSL Zertifikate für TLS (https://…) kostenfrei per Let’s Encrypt zu erstellen, verzichten leider noch einige Anbieter von Webseiten darauf und nutzen selbstzertifizierte Zertifikate. Da diese – wie der Name schon sagt – nicht von einem bekannten Zertifizierer, sondern selbst erstellt sind, wird diesen Zertifikaten von curl nicht vertraut und er verweigert Zugriff auf den Server.
Mit der Option -k vertraut curl diesen unsicheren (insecure) Zertifikaten.
$ curl -k https://static.mylinuxtime.de
Hierbei ist jedoch Vorsicht geboten. Es kann auch sein, dass dem Server durch eine Man-in-the-Middle – Attacke eine andere IP zugewiesen und die Daten über einen anderen Server geleitet werden. Die Übertragung von sensiblen Daten sollte hierüber nicht erfolgen solange man nicht sicher ist, dass Weg zum Server korrekt und direkt ist.
Verbindungsinformationen anzeigen
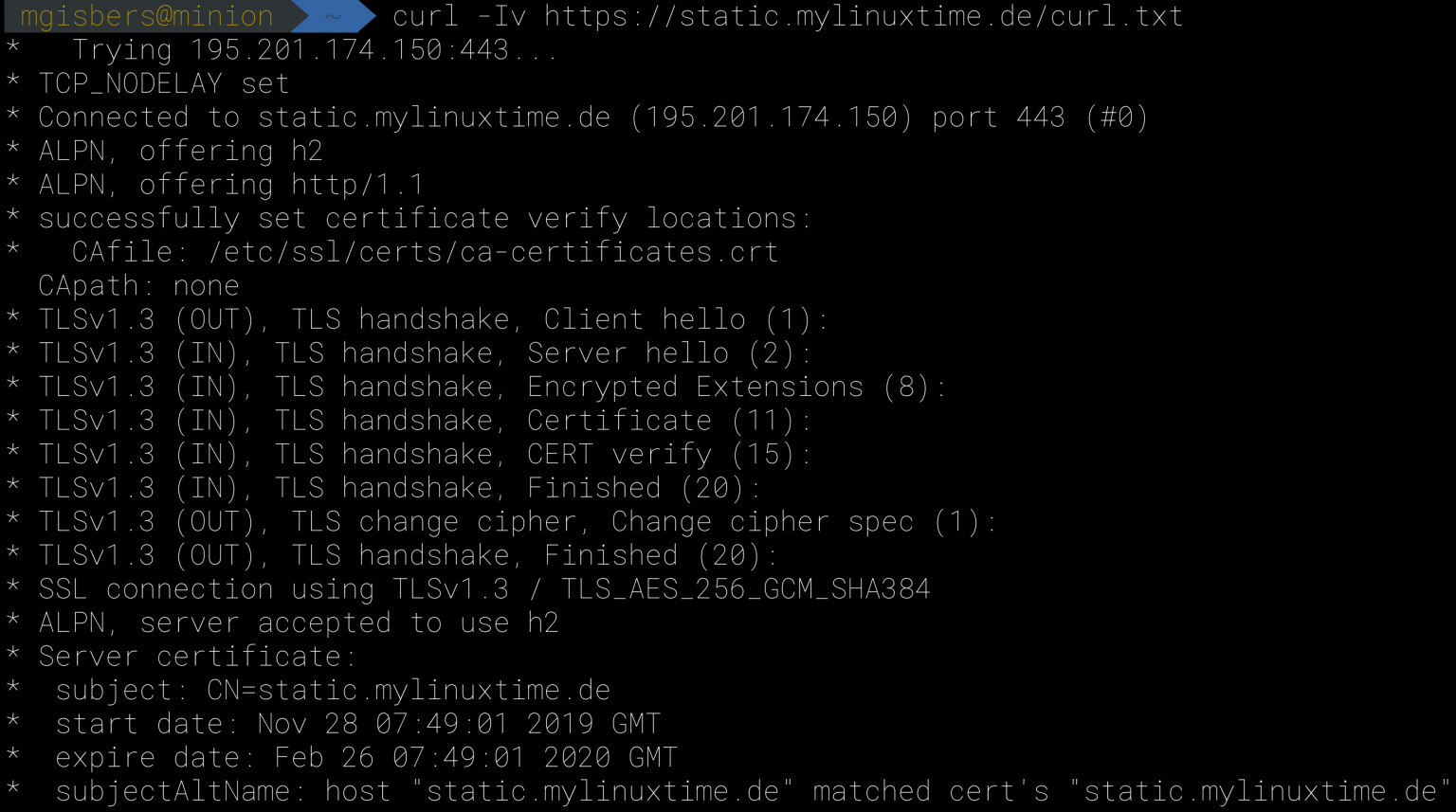
Ein wichtiges Bordmittel um die Verbindungsinformationen und damit auch z. B: die Information über den Ablauf oder Herausgeber eines Zertifikats herauszubekommen stellt curl mit der Option -v zur Verfügung.
$ curl -v https://static.mylinuxtime.de/curl.txt
Ohne weitere Information gibt der Aufruf auch den Inhalt der Datei aus. Die bereits bekannten Optionen (-o / -O) verhindern dies. Alternativ kann die Option -I nur die Header – Informationen der Datei statt des Dateiinhalts abrufen.
$ curl -Iv https://static.mylinuxtime.de/curl.txt
Umleitungen folgen
Umleitungen auf Webseiten helfen z. B. Dateien unter einem Namen anzusprechen, aber die jeweils aktuelle Version darunter abzulegen.
Trifft curl auf eine solche Umleitung beendet es seine Aufgabe und die Datei oder Ausgabe ist leer. Mit -v aufgerufen ist dann die Location Zeile sichtbar in der die URL steht in der das neue Ziel ist.
Passend zu Location lautet die Option um allen Umleitungen zu folgen -L.
Download weiterführen
Falls ein Download eine größeren Datei vorzeitig abbricht wäre es sinnvoll an der Stelle den Download weiterzuführen an der er abbrach. Die Grundeinstellung bei curl ist bei erneutem Aufruf die Datei vom Anfang an neu zu laden. Mit der Option -C lässt sich die Position für den Dateidownload angeben. Als Argument benötigt diese Option die Position ab der die Datei heruntergeladen werden soll. Das ist entweder die Position in Bytes oder - (Bindestrich). Bei Angabe des - versucht curl die Position für die Fortführung des Downloads selber zu bestimmen.
$ curl -C - -O https://mirror.mylinuxtime.de/nepulinux/nepulinux-latest.iso
So schön sich diese Option auch anhört. Der Server muss dafür mitspielen und das Range – Kommando unterstützen. Ansonsten startet der Download am Anfang der Datei.